
解决方案 > 万方大数据平台
基于云与大数据的解决方案帮助企业成功转型
1平台概述
当前数据已经渗透到每一个行业和业务职能领域,逐渐成为重要的生产因素,对于海量数据的运用将预示着新一波生产率增长和社会各行业变革的到来,在全球已经全面进入信息时代的今天,据IDC预测,全球大数据市场规模有望在2017年达530亿美元,并在未来几年内依然保持30%以上的年复合增长率。大数据机主要针对国家面向大型企业应用的共性云计算基础平台研制,基于分布式算法、数据管理技术,提高大数据挖掘与智能服务的能力。大数据机的研制符合国家信息安全政策导向,从CPU芯片、服务器系统设计和制造到操作系统、共性支撑软件、虚拟化技术和系统集群实现了实现了全栈式、一体化数据治理支撑。
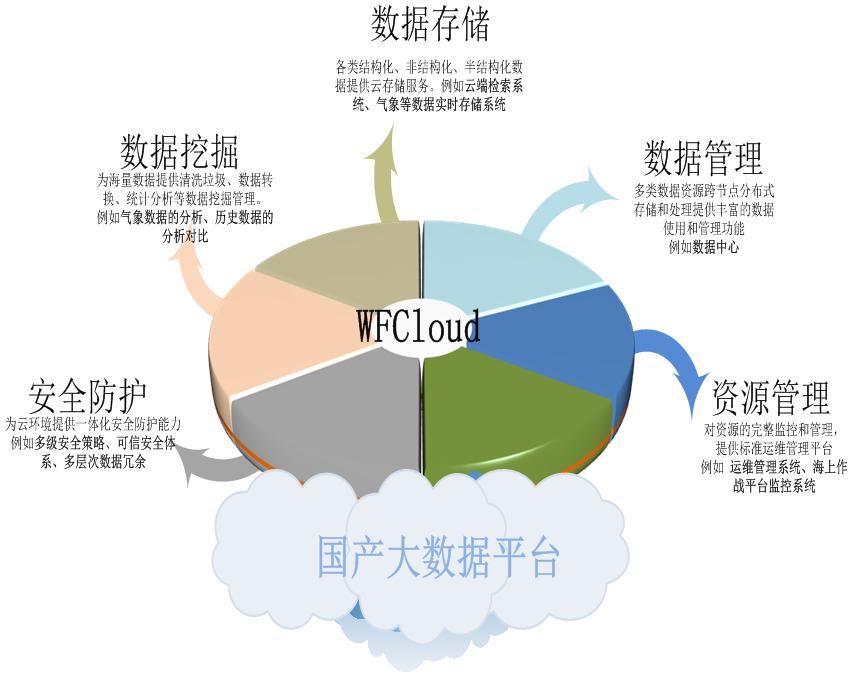
图1 国产大数据平台
WFCloud大数据平台处于系统的平台服务层,是龙芯、申威、飞腾等处理器平台上定制开发的大数据处理软件,在大数据机集群上,通过虚拟化为大数据处理提供资源池,形成大数据处理集群,软件在集群上进行了充分的适配和优化,将检索查询、图算、机器学习、数据挖掘、实时数据处理等模型统一到一个基础平台下,并以一致的接口API公开,提供各类业务应用信息引接,多源数据处理的大数据平台服务,并能提供各类大数据处理、分析工具,对各类业务信息、多源数据做分析、提取,为辅助决策系统提供有效支撑。2 平台设计
WFCloud大数据平台主要解决分布式存储和计算底层实现,采用分布式集群做底层实现,利用分布式文件系统存储数据,利用分布式计算实现大数据的任务处理,辅助使用内存计算解决分布式计算写文件系统带来的速度问题。对上通过提供各类数据存储、计算以及挖掘接口,提供业务服务计算和数据支撑,在具备海量数据的情况下可以专注业务开发而无需关心底层数据组织方式,尤其是现有的一些基于Hadoop、HBase、Hive的程序可以更加简单的迁移到龙芯、申威、飞腾等处理器架构服务器系统。2.1 平台架构
WFCloud大数据平台搭建在龙芯、申威、飞腾等处理器架构服务器上,在服务器上做了大量适配和优化,并根据硬件特点进行架构重写,满足大数据使用需求。其中主要针对大数据软件的可靠性、性能调优等方面着重进行了优化和提升。大数据平台在实际生产环境中尽可能的对所有软件都提供主从双机的HA形式,采用主备或负荷分担配置,有效避免单点故障场景对系统可靠性的影响。提供大数据软件的自动化部署工具,实现一键式安装程序和一键式集群控制功能。大数据平台软件架构如下图所示。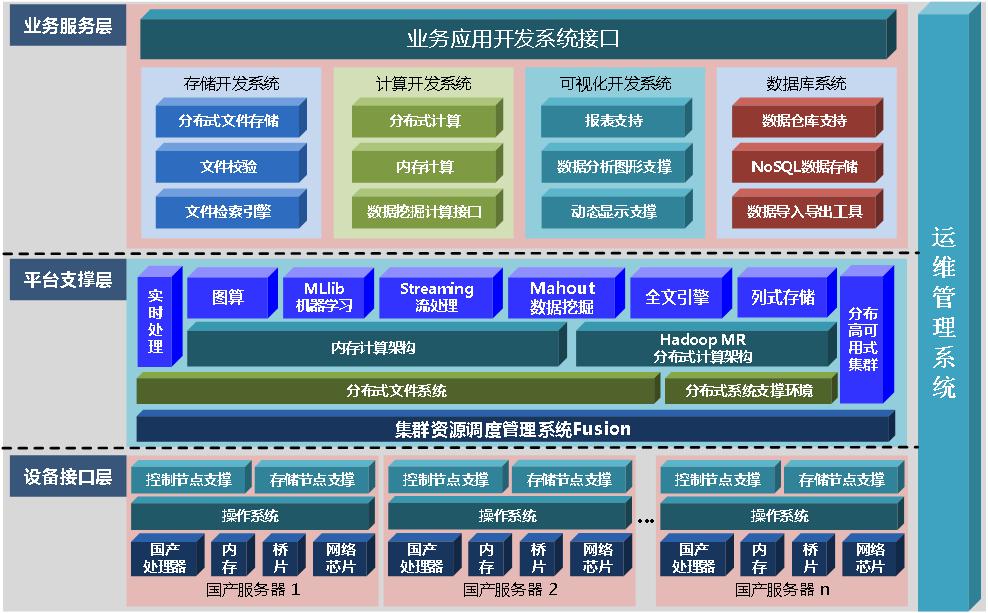
图2 大数据平台软件架构
2.2.核心组件
2.2.1 WFCloud大数据基础平台
WFCloud大数据基础平台基于开源大数据架构Apache Hadoop构建,可构建在龙芯、申威、飞腾等处理器架构服务器之上,基于HDFS构建分布式文件系统实现海量存储,基于MapReduce框架实现分布式并行处理,结合主从备份架构实现系统高可用,为大数据处理系统提供分布式计算和分布式存储能力,为上层数据库系统和其他应用系统提供平台支撑。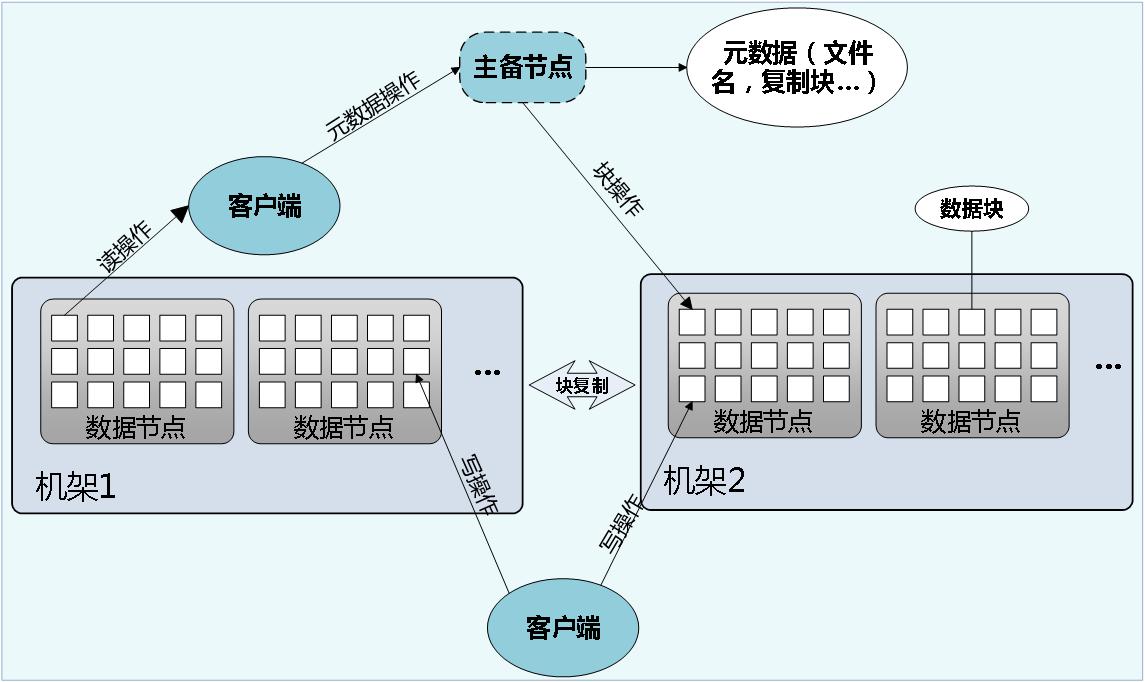
分布式存储是一个主/从(Master/Slave)体系结构,如上图所示。由于分布式存储的性质,存储集群拥有主备控制节点和若干数据节点。控制节点管理文件系统的元数据,数据节点则存储实际的数据。客户端通过与控制节点和数据节点的交互访问文件系统。客户端联系控制节点以获取文件的元数据,而真正的文件I/O操作是直接和数据节点进行交互的。
WFCloud大数据基础平台通过冗余备份、副本存放、心跳检测、安全模式、数据完整性检测、空间回收、元数据磁盘失效和快照等方法可以有效保障分布式文件系统的可靠性。平台采用Yarn作为资源管理系统,可以为各类应用程序进行资源管理和调度。基于龙芯、申威、飞腾等处理器平台优化的MapReduce框架提供快速并行处理大量数据的能力,作为分布式数据处理模式以及执行环境。
WFCloud大数据基础平台针对不同的应用场景和不同的应用侧重点,如存储、离线计算、分布式计算等方向,能够有针对性地对配置进行优化,具备高度的可定制性和扩展性。
2.2.2 WFCloud大数据内存计算框架
WFCloud大数据内存计算框架是基于开源框架Apache Spark构建,针对龙芯、申威、飞腾等处理器平台将其相关的集群软件、监控软件进行了重新定制开发。Spark是一个围绕速度、易用性和复杂构建的大数据处理框架。它提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求。Spark使用了内存内运算技术,能在数据尚未写入硬盘时即在内存内分析运算。Spark项目主要由RDDs(弹性分布式数据集)、Spark SQL、Spark Streaming、Spark MLib和Spark GraphX这几个要素组成。WFCloud大数据内存计算框架的特点如下:
● 支持分布式内存计算
● 支持迭代式的计算
● 兼容Hadoop系统文件读写方式
● 计算过程容错
● 支持多种语言开发应用(Scala/Java/Python)
● 计算能力线性扩展
WFCloud大数据内存计算框架是基于内存的迭代计算框架(如图4所示),适用于需要多次操作特定数据集的应用场合,如机器学习,图挖掘算法以及交互式数据挖掘算法等。在计算过程中需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密度较大的场合,受益则相对较小。由于弹性数据集的特性,不适用于异步细粒度更新状态的应用,例如Web应用服务的数据存储。
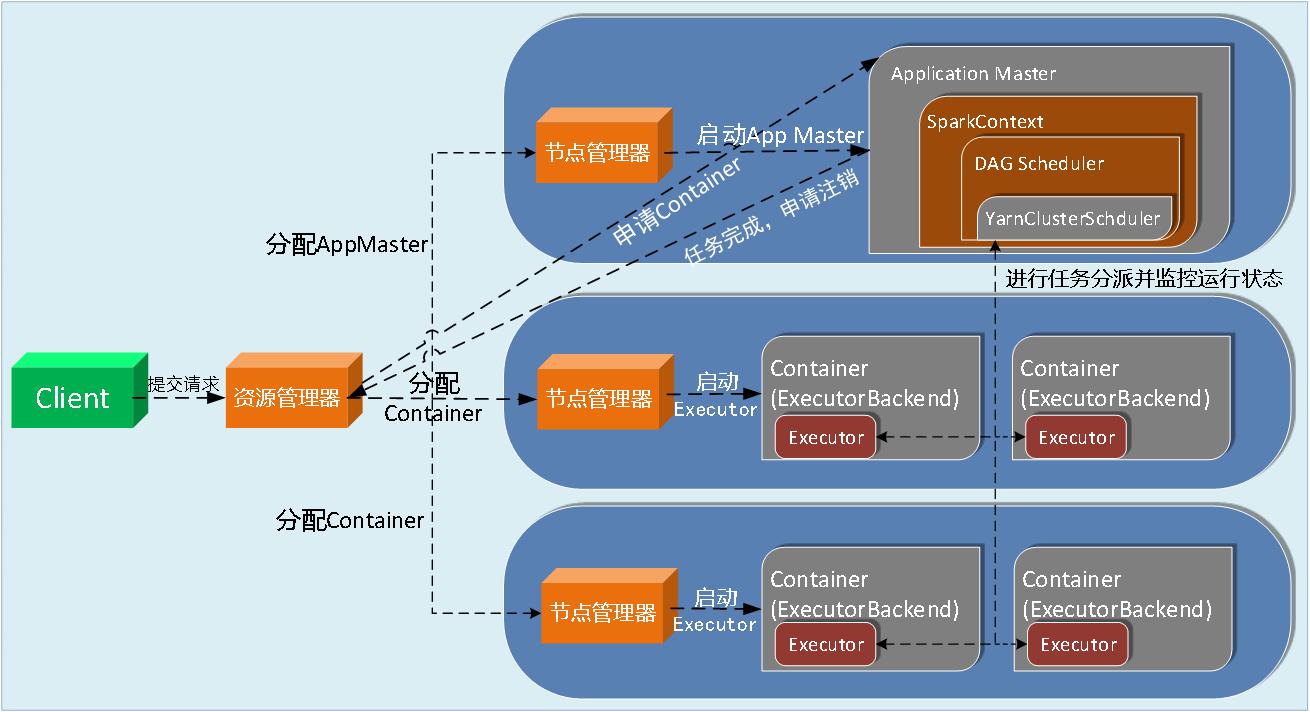
WFCloud大数据内存计算框架中计算的数据可以来自多个数据源,如Local File、HDFS等。WFCloud云计算平台使用HDFS作为其底层数据存储,用户能够快速的从MapReduce切换到WFCloud大数据内存计算框架,可以一次读取大规模的数据进行并行计算。在计算完成后,将计算结果存储到HDFS中,WFCloud大数据内存计算框架可以提供比MapReduce高10到100倍的性能。WFCloud大数据内存计算框架作为计算引擎,还支持小批量流式处理、离线批处理、SQL查询、数据挖掘,避免用户在这几类不同的系统中加载同一份数据带来的存储和性能上的开销。
在龙芯、申威、飞腾等服务器与X86设备性能存在差距的情况下,采用内存计算框架能在一定程度上弥补MapReduce在执行性能上的缺陷,如中间结果输出、数据格式和内存分布、执行策略以及任务调度的开销等方面的提升。
2.2.3 WFCloud大数据库系统
各类型军事信息系统中,数据库支撑了各种类型数据的存储、查询和统计分析等功能,但随着一些特定类型数据的数据量的不断增长,如传感器、目标轨迹和日志信息数据等,已达到普通数据库存储和访问的极限,NoSQL数据库访问性能和存储拓展性方面的优越性成为解决问题的关键。关系型数据库不再是唯一选择,数据库领域正进入混合持久化时代,即采用多种数据库解决方案,并使用不同数据存储模型,这种解决数据持久化存储问题的混合方式逐渐被采纳。WFCloud大数据库系统(WFBase)基于开源数据库Apache HBase构建,是高可靠、高性能、面向列、可伸缩的分布式数据库,能够提供海量数据的存储功能,大致架构如图5所示。大数据数据库基于One Rule Them All设计思想,用于处理半结构化和非结构化数据的存储和检索,为业务系统,数据仓库构建和数据挖掘提供数据库级数据存储和检索,方便应用开发。系统紧密结合龙芯、申威、飞腾等服务器特性,充分发挥了硬件性能,提升了数据库系统的整体性能。
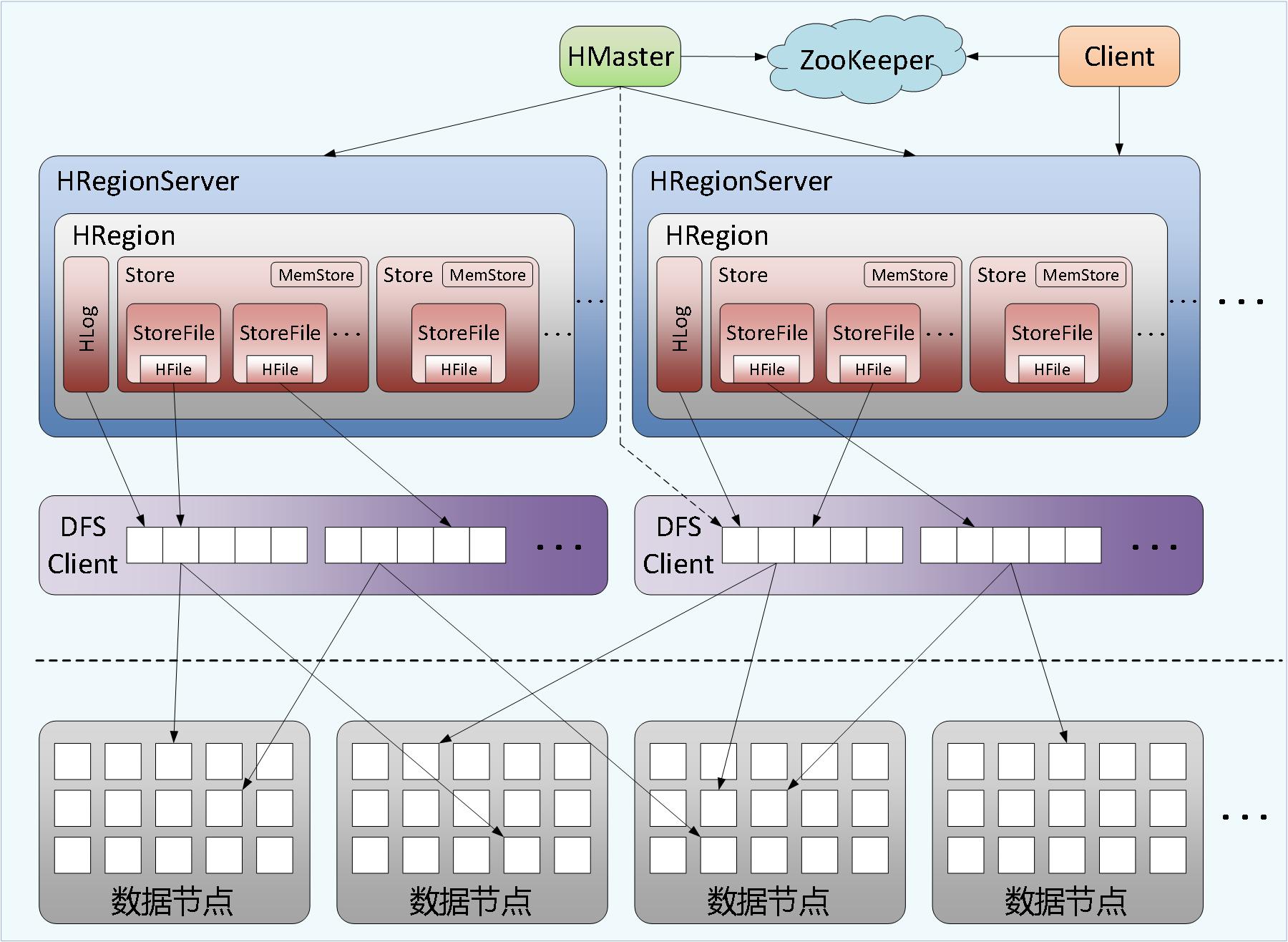
图5 WFBase架构
WFBase利用HDFS作为其文件存储系统,除了WFBase产生的一些日志文件,WFBase中的所有数据文件都可以存储在HDFS文件系统上。HDFS为WFBase提供了高可靠性的底层存储支持。
WFBase适合于存储大表数据(表的规模可以达到数十亿行以及数百万列),并且对大表数据的读、写访问可以达到实时级别,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。WFBase利用ZooKeeper作为协同服务,可使用WFCloud大数据内存计算框架和MapReduce来处理WFBase中的海量数据。
2.2.4 WFCloud大数据仓库
WFCloud大数据仓库基于开源数据仓库Apache Hive构建,主要提供类似SQL的语言操作结构化数据存储服务和基本的数据分析服务。WFCloud大数据仓库为单实例的服务进程,提供服务的原理是将WQL编译解析成相应的MapReduce或者HDFS任务。WFCloud大数据仓库作为一个基于HDFS和MapReduce架构的数据仓库(如图6所示),其主要能力是通过对WQL(WFCloud Query Language)编译和解析,生成并执行相应的MapReduce任务或者HDFS操作。
WFCloud大数据仓库主要特点如下:
- 海量结构化数据分析汇总
- 将复杂的MapReduce编写任务简化为SQL语句
- 灵活的数据存储格式,支持JSON,CSV,TEXTFILE,RCFILE,SEQUENCEFILE这几种存储格式
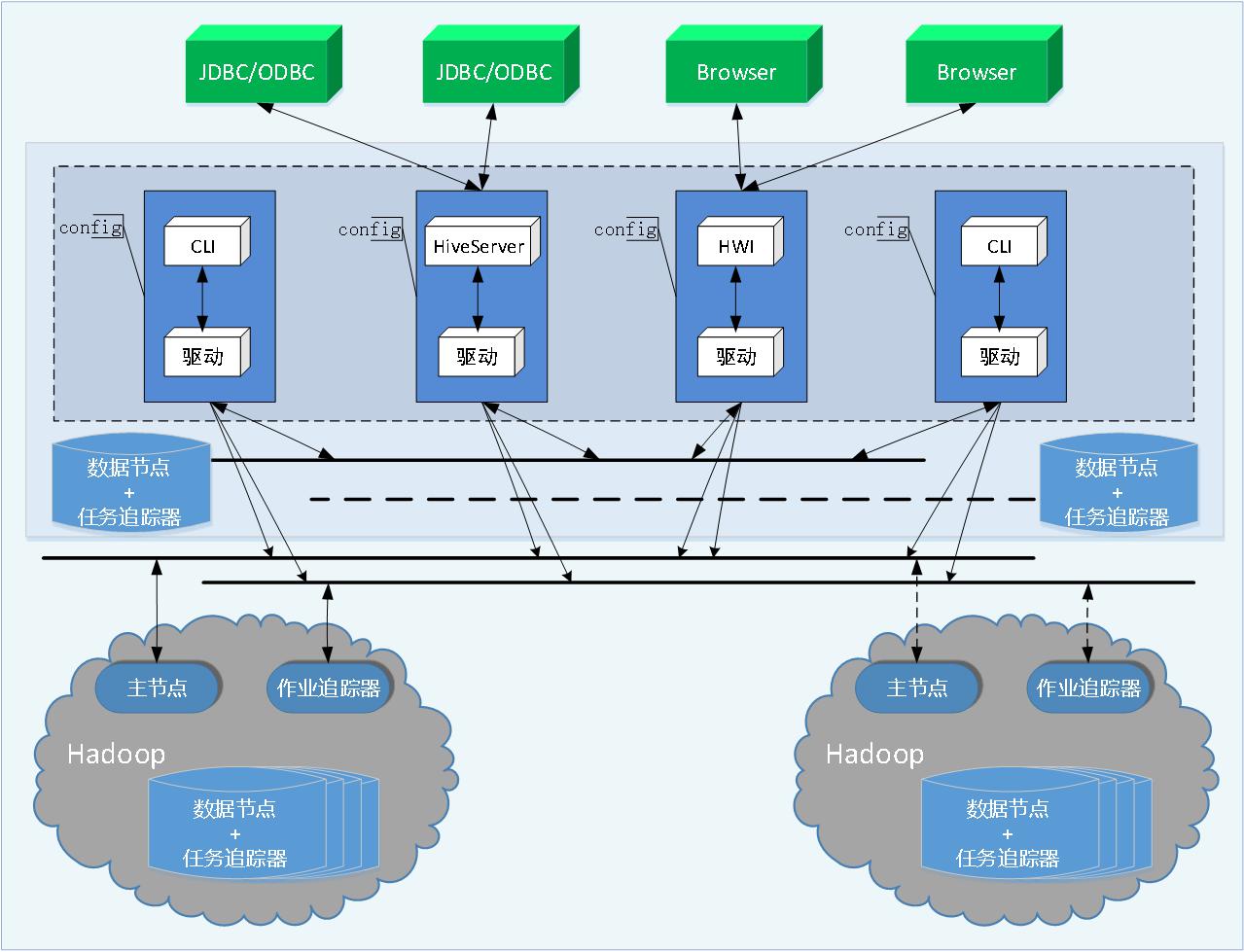
WFCloud大数据仓库包括如下相关组件:
- 用户接口:包括WFCloudshell,Thrift客户端,Web管理
- Thrift服务器:当WFCloud大数据仓库以服务器模式运行时,可以作为Thrift服务器,供客户端连接
- 元数据库:通常存储在关系型数据库(MySQL、Derby等)中
- 解析器:包括解释器、编译器、优化器、执行器,通过一系列的处理对HiveQL查询语句的词法分析、语法分析、编译、优化以及查询计划的生成。查询计划由MapReduce调用执行
3 案例
3.1 信息服务中心大数据融合平台
大数据融合平台部署在网络上,主要为海量多源异构数据提供实时入库、实时检索、实时分析等功能。同时提供分布式数据处理平台,具备流数据处理和数据挖掘能力。大数据融合平台数据处理层结构如下图所示: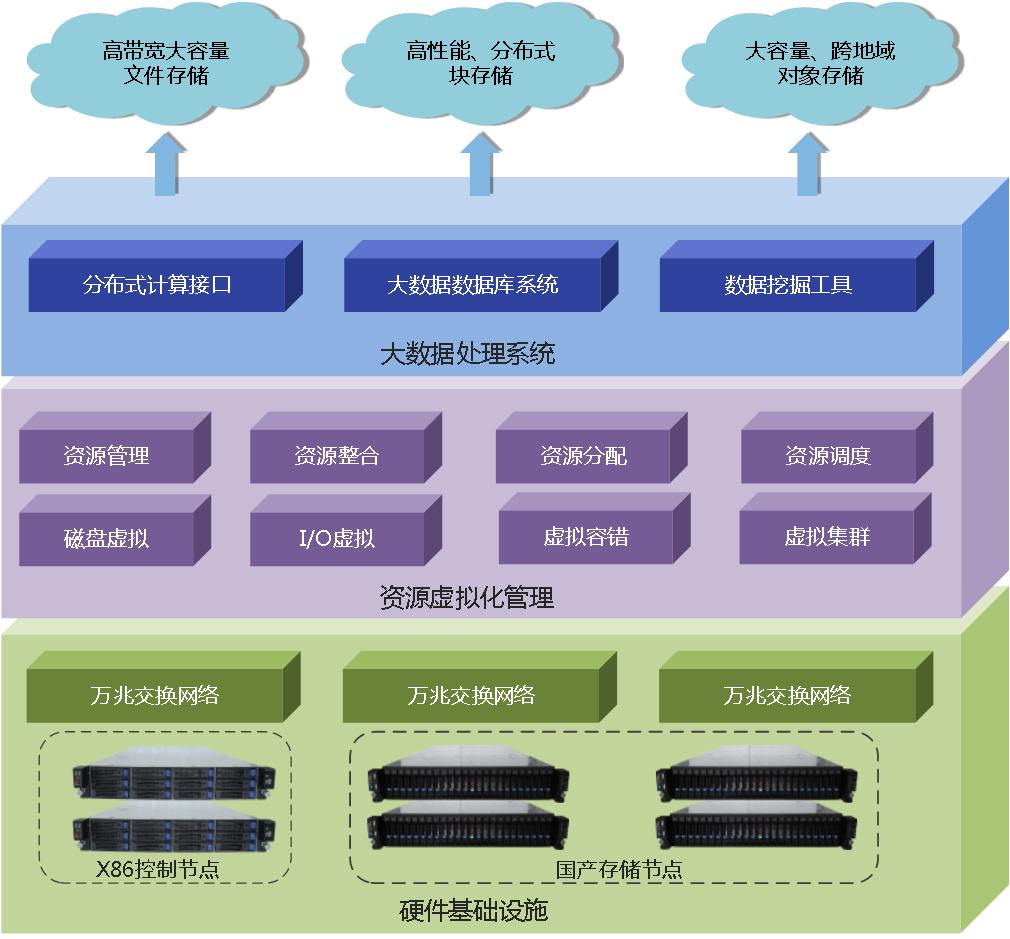
大数据融合平台基于分布式文件系统构建,集成Hadoop分布式计算平台,支持传统MapReduce和内存计算的分布式计算架构,具有超强的分布式计算能力,能支持从TB级乃至PB级数据的快捷、高效处理。
大数据融合平台的核心为数据库系统,主要解决海量数据存储与海量数据高速检索两个问题。大数据融合平台基于SQL on Hadoop自主研制大数据数据库系统,解决结构化和非结构化数据存储,对入口数据进行实时索引,对数据进行分析、分割、提取后将其存储在大数据数据库系统。同时紧密结合硬件平台,基于平台进行优化,充分发挥硬件性能,提升数据库性能。
数据处理层支持实时处理、流处理、图算以及数据挖掘,数据挖掘可以基于数据库中数据进行检索,处理和建模,支持数据的深度挖掘和商业智能分析。
3.2 目标区气象保障系统
目标区气象保障系统是用于保障打击目标区域环境判定的专用系统。专用气象保障系统近17个子系统,由信息接收处理、精细化预报预警、决策支持、保障应用和业务支撑等分系统组成,各分系统的后台处理单元采用龙芯、申威、飞腾等服务器设备。气象数据是一类非常典型的非结构化数据,在实际应用中其日增量达数十TB。为满足该项目需求,建立一个集成各类应用服务、数据预处理、实时存储、快速检索、智能分析以及二、三维可视化展示为一体的气象保障大数据处理平台。
气象保障系统软件框架如图所示:
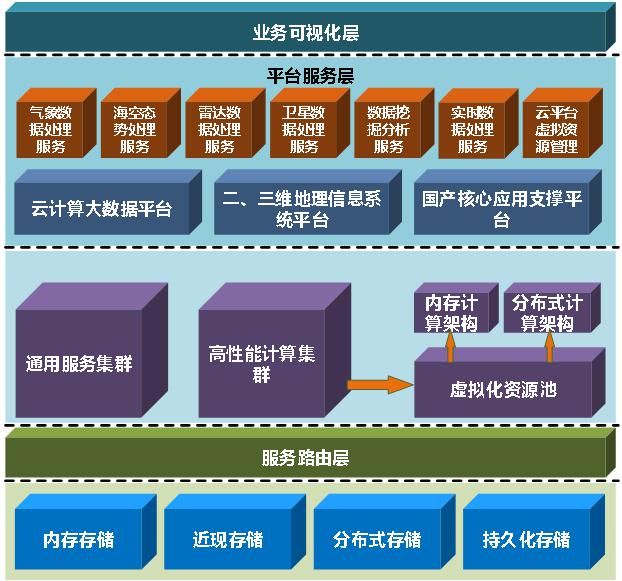 图8气象保障大数据平台应用拓扑
图8气象保障大数据平台应用拓扑数据存储层是业务的重要部分,其中内存存储采用内存数据库Redis进行集群搭建,对需要实时处理的数据进行有效快速处理;持久化存储采用传统达梦数据库集群搭建,对需要持久化的数据进行存储备份,起到安全防护作用;分布式文件存储采用MongoDB数据库进行集群搭建,对非关系型数据进行快速有效存储,供多用户进行实时访问;近线存储由WFBase集群搭建,主要用于存储访问量不大且访问性能较高的应用,同时要求设备具有相当大的存储容量和灵活的集群伸缩性。
平台服务层为业务应用提供基础服务及系统平台,主要包括云计算大数据平台及二、三维地理信息系统平台。数据服务层针对具体应用可进行弹性插件式扩展。数据处理服务包括数据分发、数据接收两部分。
业务可视化层是为用户提供数据分析、推演的展示单元,通过终端可对气象数据实时分析和服务监控。
整个气象保障系统核心数据存储和处理部分主要利用WFCloud大数据平台构建,实现系统的国产化的同时保障了系统处理性能。
3.3某数据中心建设
该项目以申威大数据机和睿思操作系统为基础平台,提供虚拟化和大数据处理技术,完成海量非结构化数据的存储和检索平台的搭建。为上层传统数据库应用、数据挖掘应用、数据可视化提供底层支撑。分布式处理平台构建在申威大数据机集群上,利用神威虚拟化技术扩充集群规模,采用分布式文件系统实现分布式存储,利用分布式计算和Map Reduce设计实现分布式计算框架,结合主从备份架构实现系统高可用,为神威大数据处理系统提供分布式计算和存储能力,具体软件架构如图所示。
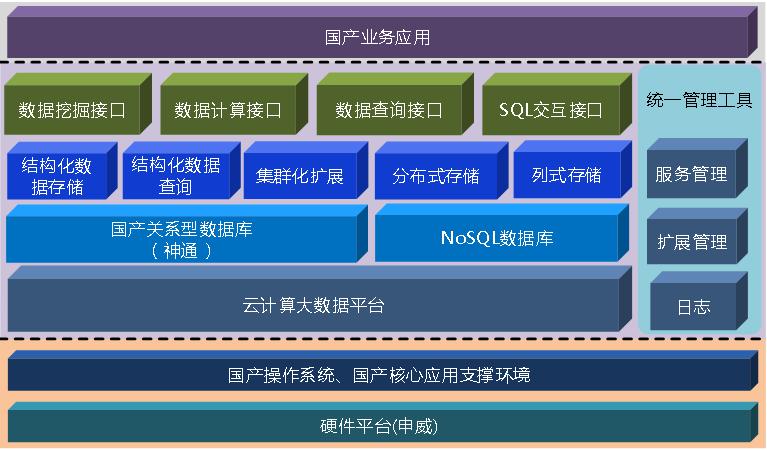
项目具体实施分为以下几步:
1)申威平台下的分布式处理平台的移植和优化;
2)利用WFCloud大数据平台构建分布式处理平台系统、WFBase数据库的具体实施、测试;
3)大数据平台搭建后,和神通数据库进行交互使用。提供相关数据挖掘和检索接口,提供基础平台应用系统移植支撑,提供数据交互模块接口;
4)与神通数据库共同完成数据库测试工作。
5)与南大通用共同完成GBase8A数据库测试工作。
3.4某学院申威大数据平台建设
该项目打造以申威大数据机和睿思操作系统为基础平台,虚拟化和大数据处理技术为核心支撑的国防大数据信息融合平台。国防作为对安全要求极高的行业,对龙芯、飞腾、申威等基础软硬件尤为青睐。申威大数据一体化解决方案,从硬件、操作系统、大数据软件、虚拟化软件、应用接口几大部分均采用自研技术,并融合安全中间件和安全数据库,为国防大数据建设新型信息化融合平台。
为满足某学院信息融合中心的信息化研制需求,需完成基础环境、平台应用以及系统服务三个层次的建设工作。其中,平台应用层中核心应用支撑环境是较为重要的环节之一,包含对基础库、基础中间件、基础开发运行环境、基础开发驱动等系统软件的融合搭建。WFCloud大数据基础平台、WFCloud大数据内存计算框架以及WFBase系统基于软硬件基础环境(申威服务器)进行建立。结合国内化先进的云计算大数据架构、技术,通过源码重构、软件架构重构,形成了申威大数据平台架构,大致如图所示。
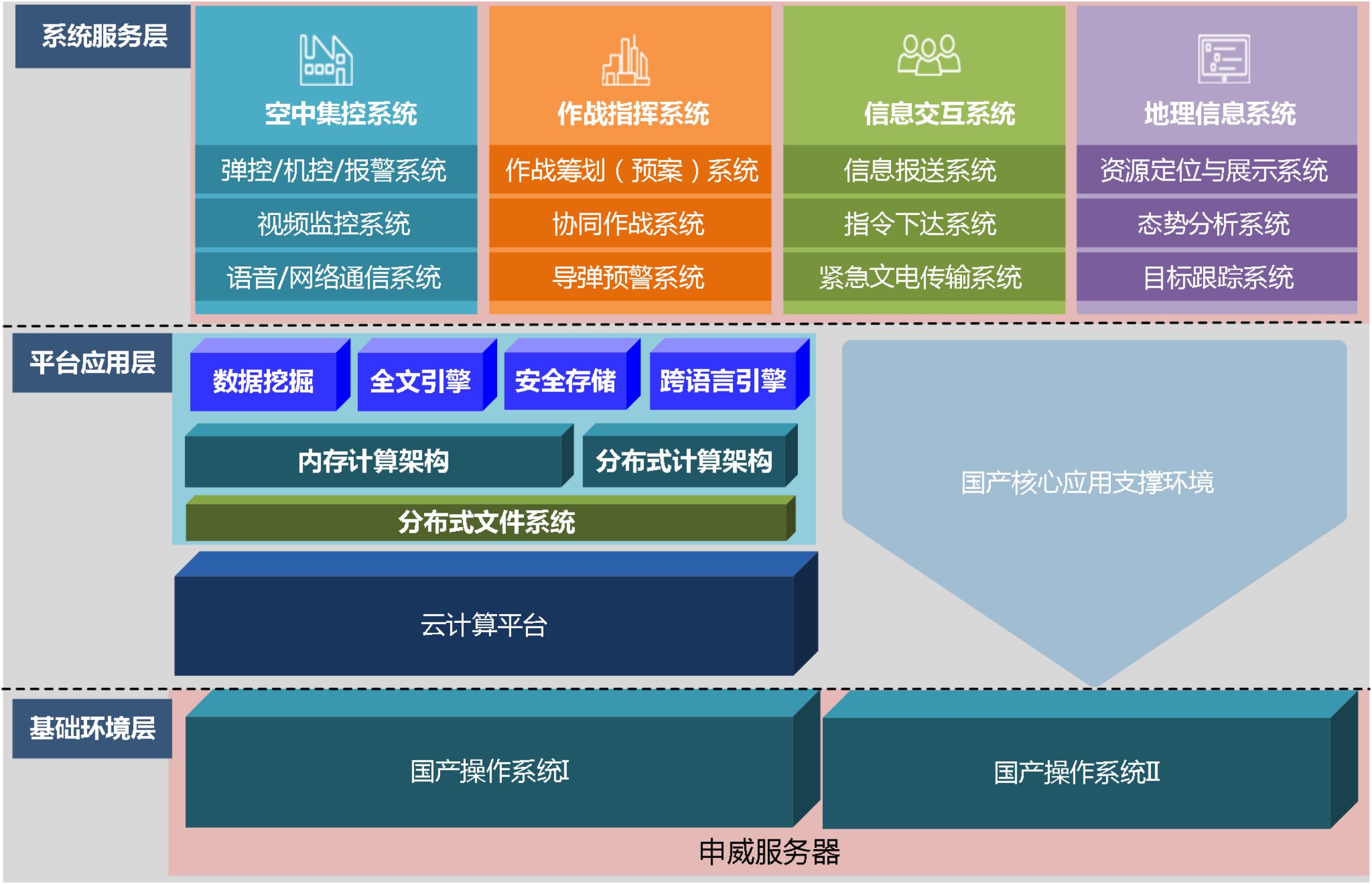
操作系统依赖于硬件平台,但又有其特殊性。解决了开源Linux的移植、基础库移植、驱动的移植等问题,然后技术人员进行优化适配。核心应用支撑环境就是为了建立一个用户反馈和技术人员优化的一个一体化平台。根据用户对应用的指标需求,结合操作系统开源基础软件的优化,解决用户使用的难题。